
Improving Retrieval-Augmented Generation (RAG) involves classifying queries based on user intent & focusing on context. Also utilising SLMs and fine-tuning to deliver more accurate & relevant results.
改进检索增强生成 (RAG) 涉及根据用户意图对查询进行分类并关注上下文。还利用 SLM 和微调来提供更准确和相关的结果。
In Short 简而言之
Selecting the right RAG (Retrieval-Augmented Generation) architecture depends primarily on the specific use case and implementation requirements, ensuring the system aligns with task demands.
选择正确的 RAG(检索增强生成)架构主要取决于特定的用例和实施要求,确保系统符合任务需求。
Agentic RAG is set to grow in importance, aligning with the concept of Agentic X, where agentic abilities are embedded within personal assistants, workflows, and processes.
Agentic RAG 的重要性将与日俱增,这与Agentic X的概念相一致,其中代理能力嵌入到个人助理、工作流程和流程中。
Here, the “X” represents the boundless adaptability of agentic systems, enabling seamless task automation and informed decision-making across diverse contexts for enhanced organisational efficiency and autonomy.
在这里,“X”代表代理系统的无限适应性,可实现无缝任务自动化和跨不同环境的明智决策,从而提高组织效率和自主权。
Synthesising diverse document sources is crucial for addressing complex, multi-part queries effectively.
综合不同的文档源对于有效解决复杂的多部分查询至关重要。
Introduction 介绍
The challenge of delivering an accurate RAG implementation includes retrieving relevant data, interpreting user intent accurately, and leveraging LLMs’ reasoning abilities for complex tasks.
提供准确的 RAG 实施的挑战包括检索相关数据、准确解释用户意图以及利用LLMs对复杂任务的推理能力。
Reasoning can be enhanced via an Agentic approach to RAG like ReAct, where a reasoning and act sequence of events are created.
推理可以通过 RAG 的代理方法(如 ReAct)来增强,其中创建事件的推理和行动序列。
Something I found interesting from this study is the fact that it states that there is no single solution that fits all data-augmented LLM applications.
我从这项研究中发现有趣的是,它指出没有单一的解决方案适合所有数据增强的LLM应用程序。
Context refers to the information surrounding a conversation that helps the AI understand the user’s intent and provide relevant, coherent responses.
上下文是指围绕对话的信息,有助于人工智能理解用户的意图并提供相关、连贯的响应。This includes factors such as the user’s previous inputs, the current task, the environment, and any external data that might influence the conversation.
这包括用户之前的输入、当前任务、环境以及可能影响对话的任何外部数据等因素。Effective context handling enables the AI to maintain a consistent and personalised dialogue, adjusting responses based on the ongoing interaction and ensuring that the conversation feels natural and meaningful.
有效的上下文处理使人工智能能够保持一致和个性化的对话,根据正在进行的交互调整响应,并确保对话感觉自然且有意义。
User Intent Detection 用户意图检测
In many instances, system underperformance stems from either failing to pinpoint the main focus of a task or from tasks that require a combination of skills, which must be carefully separated for optimal results.
在许多情况下,系统性能不佳源于未能确定任务的主要焦点,或者源于需要多种技能组合的任务,必须仔细区分这些技能以获得最佳结果。
Intent refers to the underlying purpose or goal behind a user’s input, representing what the user wants to achieve or communicate through their query.
意图是指用户输入背后的潜在目的或目标,表示用户希望通过查询实现或传达的内容。Recognising intent allows the AI system to respond appropriately.
识别意图可以让人工智能系统做出适当的反应。
RAG Data Classification RAG数据分类
Level 1: Explicit Fact Queries
第 1 级:明确的事实查询
Directly request specific, known facts.
直接请求具体的、已知的事实。
Queries are about explicit facts directly present in the given data without requiring any additional reasoning.
查询是关于给定数据中直接存在的明确事实,而不需要任何额外的推理。
This is the simplest form of query, where the model’s task is primarily to locate and extract the relevant information. When a user asks a question, the RAG implementation targets a fact contained in the chunked data.
这是最简单的查询形式,模型的任务主要是定位和提取相关信息。当用户提出问题时,RAG 实现的目标是分块数据中包含的事实。

Level 2: Implicit Fact Queries
第 2 级:隐式事实查询
Seek facts indirectly, needing interpretation to identify the answer.
间接寻求事实,需要解释才能找到答案。
Queries are about implicit facts in the data, which are not immediately obvious and may require some level of common sense reasoning or basic logical deductions.
查询涉及数据中隐含的事实,这些事实并不是立即显而易见的,可能需要一定程度的常识推理或基本逻辑推论。
The necessary information might be spread across multiple segments or require simple inferencing.
必要的信息可能分布在多个部分或需要简单的推理。
For instance, the question What is the majority party now in the country where Canberra is located? can be answered by combining the fact that Canberra is in Australia with the information about the current majority party in Australia.
例如,这个问题 What is the majority party now in the country where Canberra is located? 可以结合堪培拉位于澳大利亚的事实和澳大利亚目前多数党的信息来回答。
In level two we start to see the introduction of reasoning and action elements, hence a more agentic approach to RAG.
在第二级中,我们开始看到推理和行动元素的引入,因此 RAG 的方法更加代理。
Level 3: Interpretable Rationale Queries
第 3 级:可解释的基本原理查询
Focus on understanding reasoning behind facts and require data that supports logical explanation.
注重理解事实背后的推理,并需要支持逻辑解释的数据。
These queries require both factual knowledge and the ability to interpret and apply specific domain-based guidelines that are essential to the context of the data.
这些查询既需要事实知识,又需要解释和应用对数据上下文至关重要的特定领域指南的能力。
Such rationales are often provided in external resources but are rarely encountered in the initial pre-training of a general language model.
这些基本原理通常在外部资源中提供,但在通用语言模型的初始预训练中很少遇到。
For example, in financial auditing, an LLM may need to follow regulatory compliance guidelines to assess if a company’s financial statements meet standards.
例如,在财务审计中, LLM可能需要遵循监管合规指南来评估公司的财务报表是否符合标准。
Similarly, in technical support, it may need to follow troubleshooting workflows to assist users, ensuring responses are precise and align with established protocols.
同样,在技术支持中,可能需要遵循故障排除工作流程来帮助用户,确保响应准确并符合既定协议。
Level 4: Hidden Rationale Queries
第 4 级:隐藏的基本原理查询
Seek deeper insights, often requiring context-based reasoning to uncover underlying meanings or implications.
寻求更深入的见解,通常需要基于上下文的推理来揭示潜在的含义或含义。
This category of queries requires the AI to infer complex rationales that aren’t explicitly documented, relying on patterns and outcomes observed within the data.
此类查询需要人工智能根据数据中观察到的模式和结果来推断未明确记录的复杂原理。
These hidden rationales involve implicit reasoning and logical connections that are challenging to pinpoint and extract.
这些隐藏的基本原理涉及隐含的推理和逻辑联系,很难查明和提取。
For instance, in IT operations, a language model might analyse patterns from past incident resolutions to identify successful strategies.
例如,在 IT 运营中,语言模型可能会分析过去事件解决方案的模式,以识别成功的策略。
Similarly, in software development, the AI could draw on past debugging cases to infer effective problem-solving methods. By synthesising these implicit insights, the model can deliver responses that reflect nuanced, experience-based decision-making.
同样,在软件开发中,人工智能可以利用过去的调试案例来推断有效的问题解决方法。通过综合这些隐含的见解,该模型可以提供反映细致入微、基于经验的决策的响应。
Agentic Discovery 代理发现
Interpretable and Hidden Rationales shift the focus to a RAG system’s ability to understand and apply the reasoning behind the data.
可解释和隐藏的基本原理将焦点转移到 RAG 系统理解和应用数据背后的推理的能力。
These levels require deeper cognitive processes, where the Agentic Framework aligns with expert knowledge or extracts insights from unstructured historical data.
这些级别需要更深入的认知过程,其中代理框架与专家知识相结合或从非结构化历史数据中提取见解。

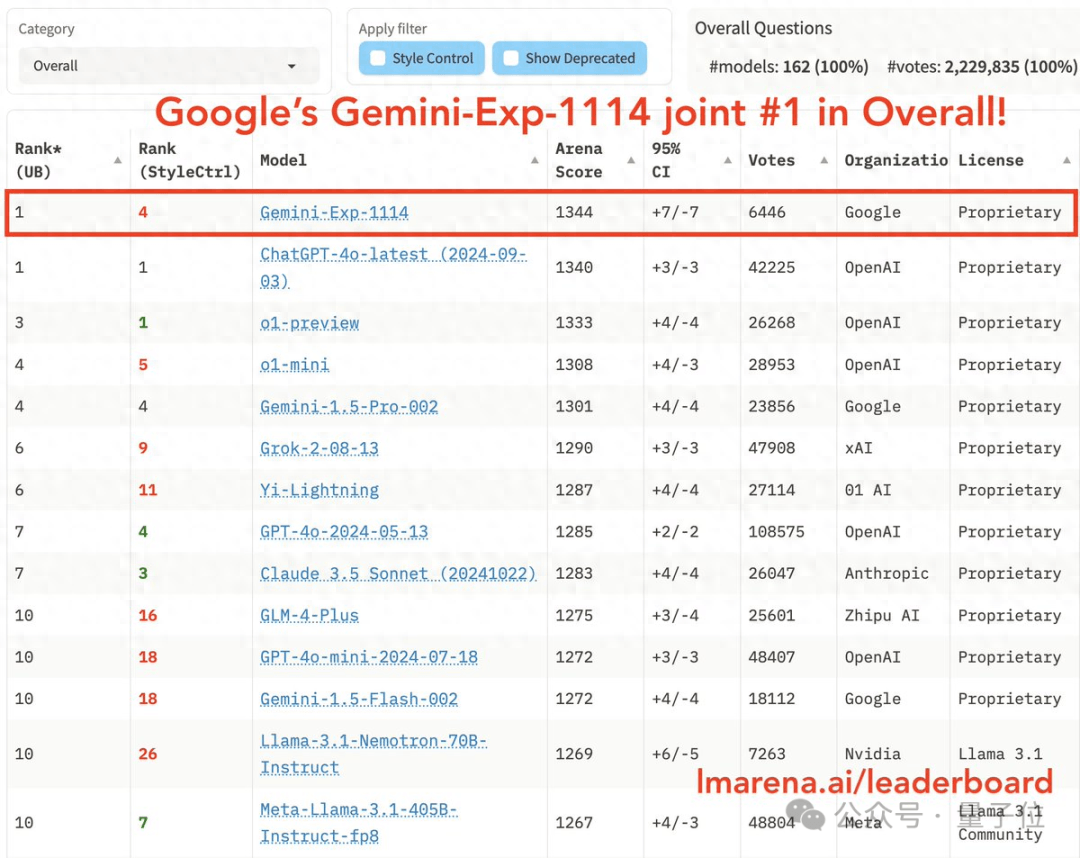
According to the study and considering the image above, there is a distinction between queries requiring explicit facts and those dependent on implicit reasoning.
根据该研究并考虑上图,需要明确事实的查询和依赖隐式推理的查询之间存在区别。
For example, a query about visa eligibility requires clear facts from the consulate’s guidelines (L3), while a question about the economic impact on a company’s future development demands an analysis of financial reports and economic trends (L4).
例如,询问签证资格需要根据领事馆的指导方针提供明确的事实(L3),而询问对公司未来发展的经济影响则需要分析财务报告和经济趋势(L4)。
The data dependency in both cases underscores the importance of external sources — whether official documentation or expert analysis.
这两种情况下的数据依赖性都强调了外部来源的重要性——无论是官方文件还是专家分析。
In both cases, providing rationales helps contextualise responses, offering not just answers but informed reasoning behind them.
在这两种情况下,提供理由有助于将回应置于情境中,不仅提供答案,还提供其背后的明智推理。

Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. From Language Models, AI Agents to Agentic Applications, Development Frameworks & Data-Centric Productivity Tools, I share insights and ideas on how these technologies are shaping the future.
首席布道者@ Kore.ai |我热衷于探索人工智能和语言的交叉点。从语言模型、人工智能代理到代理应用程序、开发框架和以数据为中心的生产力工具,我分享了有关这些技术如何塑造未来的见解和想法。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...







