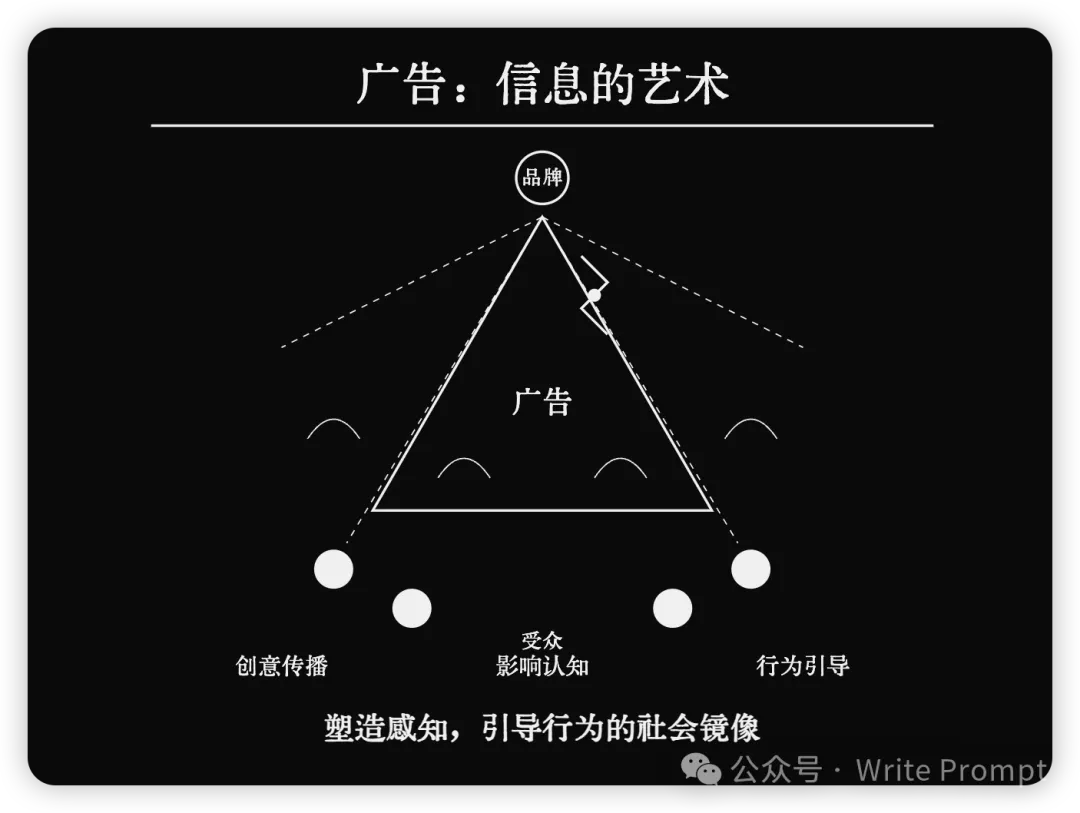
原文:https://medium.com/emalpha/your-first-rag-5844527aab4a
 In this blog, you are going to learn how to create your first RAG application for question answering over a document. Companies like Adobe are adopting these Q&A and chatting over documents as beta capabilities. Done right, these are powerful capabilities, empowering readers to gain novel insights from documents and save valuable time. Through building this app, you will encounter the multiple aspects necessary for successfully performing tasks like Q&A over documents. These include extracting information, retrieving the relevant context, and utilizing this context to generate accurate results.在本博客中,您将学习如何创建第一个用于通过文档回答问题的 RAG 应用程序。像 Adobe 这样的公司正在采用这些问答和文档聊天作为测试功能。如果做得好,这些都是强大的功能,使读者能够从文档中获得新颖的见解并节省宝贵的时间。通过构建此应用程序,您将遇到成功执行文档问答等任务所需的多个方面。其中包括提取信息、检索相关上下文以及利用此上下文生成准确的结果。
In this blog, you are going to learn how to create your first RAG application for question answering over a document. Companies like Adobe are adopting these Q&A and chatting over documents as beta capabilities. Done right, these are powerful capabilities, empowering readers to gain novel insights from documents and save valuable time. Through building this app, you will encounter the multiple aspects necessary for successfully performing tasks like Q&A over documents. These include extracting information, retrieving the relevant context, and utilizing this context to generate accurate results.在本博客中,您将学习如何创建第一个用于通过文档回答问题的 RAG 应用程序。像 Adobe 这样的公司正在采用这些问答和文档聊天作为测试功能。如果做得好,这些都是强大的功能,使读者能够从文档中获得新颖的见解并节省宝贵的时间。通过构建此应用程序,您将遇到成功执行文档问答等任务所需的多个方面。其中包括提取信息、检索相关上下文以及利用此上下文生成准确的结果。
By the end of this blog, you will have built a question answering over a 10-Q financial document, taking the Amazon Q1 2023 financial statement as the representative document, following the steps shown in figure above. First, we are going to discuss how to extract information from this document. Second, we will look at breaking the document into smaller chunks, to fit into LLM context windows. Third, we will discuss two strategies to save documents for future retrieval. One is storing the text as is for keyword based retrieval. The other is converting text into vector embeddings, for more efficient retrieval. Fourth, we will discuss saving this to a relevant database. Fifth, we will discuss obtaining relevant chunks based on user inputs. Finally, we will discuss how to incorporate relevant document chunks as part of LLM context, for generating the output. Steps 1 through 4 are referred to as the indexing pipeline, wherein documents are indexed in a database offline, prior to user interactions. Steps 5 and 6 happen in real-time as the user is querying the application.在本博客结束时,您将按照上图所示的步骤,以 Amazon 2023 年第一季度财务报表为代表文档,构建一个针对 10-Q 财务文档的问答。首先,我们将讨论如何从该文档中提取信息。其次,我们将考虑将文档分成更小的块,以适应 LLM 上下文窗口。第三,我们将讨论两种保存文档以供将来检索的策略。一种是按原样存储文本以进行基于关键字的检索。另一种是将文本转换为向量嵌入,以提高检索效率。第四,我们将讨论将其保存到相关数据库。第五,我们将讨论根据用户输入获取相关块。最后,我们将讨论如何将相关文档块合并为 LLM 上下文的一部分,以生成输出。步骤 1 到 4 称为索引管道,其中在用户交互之前在数据库中离线索引文档。步骤 5 和 6 在用户查询应用程序时实时发生。
The first step for answering questions over documents is to extract information as text for LLM. In my experience, the step of extraction is often the most overlooked factor, critical to the success of RAG applications. This is because ultimately, the quality of answers from the LLM depends on the data context that is provided. If this data has accuracy or consistency issues, this will lead to poor results overall. This section goes into the ways to extract data for RAG applications, focusing on extracting data from PDF documents in particular. You can think of the entire stage from extracting, to ultimately storing of data in the right database as similar to the traditional extract, transform, load (ETL) process where information is retrieved from an original data source, undergoes a series of modifications (including data cleansing and formatting), and is subsequently stored in a target data repository.回答有关文档的问题的第一步是将信息提取为法学硕士的文本。根据我的经验,提取步骤通常是最容易被忽视的因素,对于 RAG 应用的成功至关重要。这是因为最终,法学硕士答案的质量取决于所提供的数据上下文。如果这些数据存在准确性或一致性问题,这将导致总体结果不佳。本节介绍为 RAG 应用程序提取数据的方法,特别关注从 PDF 文档中提取数据。您可以认为从提取数据到最终将数据存储在正确的数据库中的整个阶段类似于传统的提取、转换、加载 (ETL) 过程,其中从原始数据源检索信息,经历一系列修改(包括数据清理和格式化),并随后存储在目标数据存储库中。
The basic way to extract text is to extract all the information from the PDF as a large string. This string can then be broken down into smaller chunks, to fit into LLM context windows.提取文本的基本方法是将 PDF 中的所有信息提取为一个大字符串。然后可以将该字符串分解为更小的块,以适合 LLM 上下文窗口。
PyMuDF is one such library that makes it easy to extract text from PDF documents as a string. There are other text parsers like PyPDF and PDFMiner with similar functionality. The advantage of PyMuPDF is that it supports parsing of multiple formats including txt, xps, images, etc., which is not possible in some of the other packages mentioned. Below, you can see how to extract text from the Amazon Q1–2023 PDF document using PyMuPDF, as a string:PyMuDF 就是这样一个库,可以轻松地从 PDF 文档中提取文本作为字符串。还有其他文本解析器,例如 PyPDF 和 PDFMiner,具有类似的功能。 PyMuPDF 的优点是它支持多种格式的解析,包括 txt、xps、图像等,这在提到的其他一些包中是不可能的。下面,您可以了解如何使用 PyMuPDF 从 Amazon Q1–2023 PDF 文档中提取文本作为字符串:
import requests
import fitz
import io
url = "https://s2.q4cdn.com/299287126/files/doc_financials/2023/q1/Q1-2023-Amazon-Earnings-Release.pdf"
request = requests.get(url)
filestream = io.BytesIO(request.content)
with fitz.open(stream=filestream, filetype="pdf") as doc:
#concatenating text to a string and printing out the first 10 characters
text = ""
for page in doc:
text += page.get_text()
print(text[:10])
Chunking Data 数据分块
A natural first question is — why do all this, why not just send all the text to the LLM and let it answer questions? Let’s take the Amazon Q1 2023 document for example. The entire text is ~50k characters. If you try passing all the text as context to GPT-3.5, you get an error due to the context being too long.一个自然的第一个问题是——为什么要做这一切,为什么不将所有文本发送给法学硕士并让它回答问题?我们以亚马逊 2023 年第一季度文档为例。整个文本大约有 5 万个字符。如果您尝试将所有文本作为上下文传递到 GPT-3.5,则会因上下文太长而收到错误。
LLMs typically have a token limit (each token is roughly 3/4th a word). Let’s see how to solve this with chunking. Chunking involves dividing a lengthy text into smaller sections that an LLM can process more efficiently.LLM 通常有一个令牌限制(每个令牌大约是一个单词的 3/4)。让我们看看如何通过分块来解决这个问题。分块涉及将冗长的文本分成更小的部分,以便法学硕士可以更有效地处理。
The figure below outlines how to build a basic RAG that utilizes an LLM over custom documents for question answering. The first part is splitting multiple documents into manageable chunks. The associated parameter is the maximum chunk length. These chunks should be of the typical (minimum) size of text that contain the answers to the typical questions asked. This is because sometimes the question you ask might have answers at multiple locations within the document. For example, you might ask the question “What was X company’s performance from 2015 to 2020?” And you might have a large document (or multiple documents) containing specific information about company performance over the years in different parts of the document. You would ideally want to capture all disparate parts of the document(s) containing this information, link them together, and pass to an LLM for answering based on these filtered and concatenated document chunks.下图概述了如何构建一个基本的 RAG,该 RAG 利用 LLM 而非自定义文档来回答问题。第一部分是将多个文档分割成可管理的块。相关参数是最大块长度。这些块应该具有典型(最小)文本大小,其中包含所提出的典型问题的答案。这是因为有时您提出的问题可能在文档中的多个位置都有答案。例如,您可能会问“X公司2015年至2020年的业绩如何?”您可能有一个大文档(或多个文档),其中不同部分包含有关多年来公司业绩的具体信息。理想情况下,您希望捕获包含此信息的文档的所有不同部分,将它们链接在一起,然后传递给法学硕士,以根据这些过滤和连接的文档块进行回答。

The maximum context length is basically the maximum length for concatenating various chunks together, leaving some space for the question itself and the output answer. Remember that LLMs like GPT3.5 have a strict length limit that includes all the content: question, context, and answer. Finding the right chunking strategy is crucial for building high quality RAG applications.最大上下文长度基本上是将各个块连接在一起的最大长度,为问题本身和输出答案留出一些空间。请记住,像 GPT3.5 这样的 LLM 有严格的长度限制,其中包括所有内容:问题、上下文和答案。找到正确的分块策略对于构建高质量的 RAG 应用程序至关重要。
There are different methods to chunk based on use-case. Here are five levels of chunking based on the complexity and effectiveness.根据用例有不同的分块方法。根据复杂性和有效性,这里有五个级别的分块。
- Fixed Size Chunking: This is the most basic method, where the text is split into chunks of a specified number of characters, without considering the content or structure. It’s simple to implement but may result in chunks that lack coherence or context.固定大小分块:这是最基本的方法,将文本分割成指定数量字符的块,而不考虑内容或结构。它实现起来很简单,但可能会导致块缺乏连贯性或上下文。
- Recursive Chunking: This method splits the text into smaller chunks using a set of separators (like newlines or spaces) in a hierarchical and iterative manner. If the initial splitting doesn’t produce chunks of the desired size, it recursively calls itself on the resulting chunks with a different separator.递归分块:此方法使用一组分隔符(如换行符或空格)以分层和迭代的方式将文本分割成更小的块。如果初始分割没有产生所需大小的块,它会使用不同的分隔符在生成的块上递归地调用自身。
- Document Based Chunking: In this approach, the text is split based on its inherent structure, such as markdown formatting, code syntax, or table layouts. This method preserves the flow and context of the content but may not be effective for documents lacking clear structure.基于文档的分块:在这种方法中,文本根据其固有结构进行分割,例如 Markdown 格式、代码语法或表格布局。此方法保留了内容的流程和上下文,但对于缺乏清晰结构的文档可能无效。
- Semantic Chunking: This strategy aims to extract semantic meaning from embeddings and assess the semantic relationship between chunks. It adaptively picks breakpoints between sentences using embedding similarity, keeping together chunks that are semantically related.语义分块:该策略旨在从嵌入中提取语义并评估块之间的语义关系。它使用嵌入相似性自适应地在句子之间选择断点,将语义相关的块保持在一起。
- Agentic Chunking: This approach explores the possibility of using a language model to determine how much and what text should be included in a chunk based on the context. It generates initial chunks using propositional retrieval and then employs an LLM-based agent to determine whether a proposition should be included in an existing chunk or if a new chunk should be created.主体分块:这种方法探索了使用语言模型根据上下文确定块中应包含多少文本和哪些文本的可能性。它使用命题检索生成初始块,然后采用基于 LLM 的代理来确定命题是否应包含在现有块中或是否应创建新块。
The similarity threshold is the way to compare the question with document chunks, to find the top chunks, most likely to contain the answer. Cosine similarity is the typical metric used, but you might want to weigh different metrics, such as including a keyword metric to weight contexts with certain keywords more. For example, you might want to weight contexts that contain the words “abstract” or “summary” when you ask the question to an LLM to summarize a document.相似度阈值是将问题与文档块进行比较,以找到最有可能包含答案的顶级块的方法。余弦相似度是使用的典型指标,但您可能想要权衡不同的指标,例如包含关键字指标以对具有某些关键字的上下文进行更多加权。例如,当您向法学硕士提出总结文档的问题时,您可能希望对包含“摘要”或“摘要”一词的上下文进行加权。
Let’s use simple fixed chunking in our first RAG app, splitting chunks by sentences where necessary. For this, we need to split up the texts into chunks, when they reach a provided maximum token length. The OpenAI tokenizer below, can be used to tokenize text, and calculate the number of tokens.让我们在第一个 RAG 应用程序中使用简单的固定分块,在必要时按句子分割块。为此,当文本达到提供的最大标记长度时,我们需要将文本分成块。下面的 OpenAI 分词器可用于对文本进行分词,并计算分词数量。
tokenizer = tiktoken.get_encoding("cl100k_base")
df=pd.DataFrame([text]).T
df.columns = ['text']
df['n_tokens'] = df.text.apply(lambda x: len(tokenizer.encode(x)))
This text can then be split into multiple contexts as below, for LLM comprehension, based on a token limit. For this, the text is split into sentences from the period delimiter, and sentences are appended to a chunk. If the chunk length is beyond the token limit, that chunk is truncated, and the next chunk is started. In the figure below, you can see an example of chunking by sentences, where three chunks are displayed as three distinct paragraphs.然后,可以根据令牌限制将该文本拆分为多个上下文,如下所示,以供 LLM 理解。为此,文本从句点分隔符分割成句子,并将句子附加到块中。如果块长度超出令牌限制,则该块将被截断,并开始下一个块。在下图中,您可以看到按句子分块的示例,其中三个块显示为三个不同的段落。

Here is the split_into_many function that does the same:这是执行相同操作的 split_into_many 函数:
def split_into_many(text: str, tokenizer: tiktoken.Encoding, max_tokens: int = 1024) -> list:
""" Function to split a string into many strings of a specified number of tokens """
sentences = text.split('. ') #A
n_tokens = [len(tokenizer.encode(" " + sentence))
for sentence in sentences] #B
chunks = []
tokens_so_far = 0
chunk = []
for sentence, token in zip(sentences, n_tokens): #C
if tokens_so_far + token > max_tokens: #D
chunks.append(". ".join(chunk) + ".")
chunk = []
tokens_so_far = 0
if token > max_tokens #E:
continue
chunk.append(sentence) #F
tokens_so_far += token + 1
return chunks
#A Split the text into sentences
#B Get the number of tokens for each sentence
#C Loop through the sentences and tokens joined together in a tuple
#D If the number of tokens so far plus the number of tokens in the current sentence is greater than the max number of tokens, then add the chunk to the list of chunks and reset
#E If the number of tokens in the current sentence is greater than the max number of tokens, go to the next sentence
#F # Otherwise, add the sentence to the chunk and add the number of tokens to the total
Finally, you can tokenize the entire text by calling the tokenize function, that concatenates the logic from above:最后,您可以通过调用 tokenize 函数来对整个文本进行标记,该函数连接上面的逻辑:
def tokenize(text,max_tokens) -> pd.DataFrame:
""" Function to split the text into chunks of a maximum number of tokens """
tokenizer = tiktoken.get_encoding("cl100k_base") #A
df=pd.DataFrame(['0',text]).T
df.columns = ['title', 'text']
df['n_tokens'] = df.text.apply(lambda x: len(tokenizer.encode(x))) #B
shortened = []
for row in df.iterrows():
if row[1]['text'] is None: #C
continue
if row[1]['n_tokens'] > max_tokens: #D
shortened += split_into_many(row[1]['text'], tokenizer, max_tokens)
Else: #E
shortened.append(row[1]['text'])
df = pd.DataFrame(shortened, columns=['text'])
df['n_tokens'] = df.text.apply(lambda x: len(tokenizer.encode(x)))
return df
#A Load the cl100k_base tokenizer which is designed to work with the ada-002 model
#B Tokenize the text and save the number of tokens to a new column
#C If the text is None, go to the next row
#D If the number of tokens is greater than the max number of tokens, split the text into chunks
#E Otherwise, add the text to the list of shortened texts
In the figure below, you can see how the entire dataframe looks, after running tokenize(text,500). Each chunk is a separate row, and there are 13 chunks in total. The chunk text is in the ‘text’ column, the number of tokens for that text in the ‘n_tokens’ column.在下图中,您可以看到运行 tokenize(text,500) 后整个数据框的外观。每个块都是一个单独的行,总共有 13 个块。块文本位于“text”列中,“n_tokens”列中该文本的标记数量。

Retrieval Methods 检索方法
The next step, after document extraction and chunking, is to store these documents in an appropriate format so that relevant documents or passages can be easily retrieved in response to future queries. In the following sections, you are going to see two characteristic methods to retrieve relevant LLM context: keyword based retrieval and vector embeddings based retrieval.在文档提取和分块之后,下一步是以适当的格式存储这些文档,以便可以轻松检索相关文档或段落以响应将来的查询。在以下部分中,您将看到两种检索相关 LLM 上下文的典型方法:基于关键字的检索和基于向量嵌入的检索。
Keyword Based Retrieval 基于关键词的检索
The easiest way to sort relevant documents is to do a keyword match and find documents with the highest match. For this, we need to first define a way to match documents based on keywords. In information retrieval, two important concepts form the foundation of many ranking algorithms: Term Frequency (TF) and Inverse Document Frequency (IDF).对相关文档进行排序的最简单方法是进行关键字匹配并查找匹配度最高的文档。为此,我们需要首先定义一种基于关键字匹配文档的方法。在信息检索中,两个重要的概念构成了许多排名算法的基础:词频(TF)和逆文档频率(IDF)。
Term Frequency (TF) measures how often a term appears in a document. It’s based on the assumption that the more times a term occurs in a document, the more relevant that document is to the term.术语频率 (TF) 衡量术语在文档中出现的频率。它基于这样的假设:某个术语在文档中出现的次数越多,该文档与该术语的相关性就越高。
TF(t,d) = Number of times term t appears in document d / Total number of terms in document dTF(t,d) = 术语 t 在文档 d 中出现的次数 / 文档 d 中的术语总数
Inverse Document Frequency (IDF) measures the importance of a term across the entire corpus of documents. It assigns higher importance to terms that are rare in the corpus and lower importance to terms that are common.逆文档频率 (IDF) 衡量术语在整个文档语料库中的重要性。它对语料库中罕见的术语赋予较高的重要性,对常见的术语赋予较低的重要性。
IDF(t) = Total number of documents / Number of documents containing term tIDF(t) = 文档总数 / 包含术语 t 的文档数
The TF-IDF score is then calculated by multiplying TF and IDF:然后通过将 TF 与 IDF 相乘来计算 TF-IDF 分数:
TF-IDF(t,d) = TF(t,d) * IDF(t) TF-IDF(t,d) = TF(t,d) * IDF(t)
While TF-IDF is useful, it has limitations. This is where the Okapi BM25 algorithm comes in, offering a more sophisticated approach to document ranking.虽然 TF-IDF 很有用,但它也有局限性。这就是 Okapi BM25 算法的用武之地,它提供了一种更复杂的文档排名方法。
The Okapi BM25 is a common algorithm for matching documents based on keywords, as shown in the figure below.Okapi BM25是一种常见的基于关键词匹配文档的算法,如下图所示。

Given a query Q containing keywords q1,q2,…the BM25 score of a document D is as above. The function f(qi, D) is the number of times qi occurs in D, and k1, b are constants. IDF denotes the inverse document frequency of the word qi. IDF measures the importance of a term in the entire corpus. It assigns higher importance to terms that are rare in the corpus and lower importance to terms that are common. This is used to normalize contributions of common words like ‘The’, or ‘and’ from search results. avgdl is the average document length in the text collection from which documents are drawn.给定一个包含关键字 q1,q2,… 的查询 Q,文档 D 的 BM25 分数如上。函数f(qi,D)是qi在D中出现的次数,k1、b是常数。 IDF 表示单词 qi 的逆文档频率。 IDF 衡量一个术语在整个语料库中的重要性。它对语料库中罕见的术语赋予较高的重要性,对常见的术语赋予较低的重要性。这用于规范搜索结果中常见单词(如“The”或“and”)的贡献。 avgdl 是从中提取文档的文本集合中的平均文档长度。
The BM25 formula can be understood as an extension of TF-IDF:BM25公式可以理解为TF-IDF的扩展:
- It uses IDF to weigh the importance of terms across the corpus, similar to TF-IDF.它使用 IDF 来权衡语料库中术语的重要性,类似于 TF-IDF。
- The term frequency component (f(qi,D)) is normalized using a saturation function, which prevents the score from increasing linearly with term frequency. This addresses a limitation of basic TF-IDF.使用饱和函数对术语频率分量 (f(qi,D)) 进行归一化,这可以防止分数随术语频率线性增加。这解决了基本 TF-IDF 的限制。
- It incorporates document length normalization (|D| / avgdl), adjusting for the fact that longer documents are more likely to have higher term frequencies simply due to their length.它结合了文档长度归一化 (|D| / avgdl),根据较长的文档更有可能因其长度而具有较高的术语频率这一事实进行调整。
By considering these additional factors, BM25 often provides more accurate and nuanced document ranking compared to simpler TF-IDF approaches, making it a popular choice in information retrieval systems.通过考虑这些额外因素,与更简单的 TF-IDF 方法相比,BM25 通常提供更准确、更细致的文档排名,使其成为信息检索系统中的流行选择。
The BM25 algorithm returns a value between 0 (no keyword overlaps between Query and Document) and 1 (Document contains all keywords in Query). For example, if the user input is “windy day” and the document is “It is quite windy” — the BM25 algorithm would yield a non-zero result. Here is a snippet of a Python implementation of BM25:BM25 算法返回 0(查询和文档之间没有关键字重叠)和 1(文档包含查询中的所有关键字)之间的值。例如,如果用户输入是“大风天”并且文档是“风很大”——BM25 算法将产生非零结果。以下是 BM25 的 Python 实现片段:
from rank_bm25 import BM25Okapi
corpus = [
"Hello there how are you!",
"It is quite windy in Boston",
"How is the weather tomorrow?"
]
tokenized_corpus = [doc.split(" ") for doc in corpus]
bm25 = BM25Okapi(tokenized_corpus)
query = "windy day"
tokenized_query = query.split(" ")
doc_scores = bm25.get_scores(tokenized_query)
have keyword overlap with the query.
Output:
array([0. , 0.48362189, 0. ]) #A
#A Only the second document and the query have an overlap, the others do not
The user input here is “windy day”. As you can see, there is an overlap between the second document in the corpus (“It is quite windy in Boston”), and the input, which is reflected by the second score being the highest (0.48).这里的用户输入是“大风天”。正如您所看到的,语料库中的第二个文档(“波士顿风很大”)和输入之间存在重叠,这反映在第二个文档得分最高(0.48)。
However, you also see how the third document (“How is the weather tomorrow?”) is related to the input (as both discuss the weather). We would like the third document to have some non-zero score.This is where the concept of semantic similarity and vector embeddings comes in. A classic example of this is where the user searches for “Wild West” and expects information about cowboys. Semantic search means that the algorithm is intelligent enough to know that cowboys and the wild west are similar concepts (while having different words). This becomes important for RAG as it is quite possible the user types in a query that is not exactly present in the document, for which we need a good measure of semantic similarity to find the relevant documents, according to the users intent.但是,您还可以看到第三个文档(“明天天气怎么样?”)与输入的关系(因为两者都讨论天气)。我们希望第三个文档有一些非零分数。这就是语义相似性和向量嵌入概念的用武之地。一个典型的例子是用户搜索“狂野西部”并期望有关牛仔的信息。语义搜索意味着算法足够智能,可以知道牛仔和狂野西部是相似的概念(虽然有不同的单词)。这对于 RAG 来说变得很重要,因为用户输入的查询很可能并不完全存在于文档中,为此我们需要良好的语义相似性度量来根据用户意图找到相关文档。
Vector Embeddings 向量嵌入
Vector search helps in choosing what the relevant context is when you have vast amounts of data, including hundreds or more documents.Vector search is a technique in information retrieval and machine learning that uses vector representations of data points to efficiently find similar items in a large dataset. It involves encoding data into high-dimensional vectors and using distance metrics to measure similarity between these vectors.当您拥有大量数据(包括数百个或更多文档)时,矢量搜索有助于选择相关上下文。矢量搜索是信息检索和机器学习中的一种技术,它使用数据点的矢量表示来有效地查找大型数据中的相似项目。数据集。它涉及将数据编码为高维向量并使用距离度量来测量这些向量之间的相似性。
In the figure below, you can see a simplified two-dimensional vector space:下图中,你可以看到一个简化的二维向量空间:
X-axis: Size (small = 0, big = 1)X 轴:尺寸(小 = 0,大 = 1)
Y-axis: Type (tree = 0, animal = 1)Y 轴:类型(树 = 0,动物 = 1)
This example illustrates both direction and magnitude:这个例子说明了方向和幅度:
A small tree might be represented as (0, 0)一棵小树可以表示为 (0, 0)
A big tree as (1, 0)一棵大树为 (1, 0)
A small animal as (0, 1)一只小动物为 (0, 1)
A big animal as (1, 1)大型动物如 (1, 1)
The direction of the vector indicates the combination of features, while the magnitude (length) of the vector represents the strength or prominence of those features.矢量的方向表示特征的组合,而矢量的大小(长度)表示这些特征的强度或突出程度。
This is just a conceptual example and can be scaled to hundreds or more dimensions, each representing different attributes of the data. In real-world applications, these vectors often have much higher dimensionality, allowing for more nuanced representations of complex data.这只是一个概念性示例,可以扩展到数百个或更多维度,每个维度代表数据的不同属性。在现实应用中,这些向量通常具有更高的维度,可以更细致地表示复杂数据。
The same can also be done with text as below, and yields better semantic similarity as compared to keyword search. An appropriate embedding algorithm would be able to judge which contexts are most relevant to user input, and which contexts are not as relevant, crucial for the retrieval step in RAG applications. Once this relevant context is found, this can be added to the user input, and passed to an LLM for generating the appropriate output, sent back to the user.也可以对下面的文本进行同样的操作,并且与关键字搜索相比,可以产生更好的语义相似性。适当的嵌入算法将能够判断哪些上下文与用户输入最相关,哪些上下文不那么相关,这对于 RAG 应用程序中的检索步骤至关重要。一旦找到相关上下文,就可以将其添加到用户输入中,并传递给 LLM 以生成适当的输出,然后发送回用户。

Notice how in the figure below, the vectorization is able to capture the semantic representation (i.e,. it knows that a sentence talking about a bird swooping in on a baby chipmunk should be in the (small, animal) quadrant, whereas the sentence talking about yesterday’s storm when a large tree fell on the road should be in the (big, tree) quadrant). In reality, there are more than two dimensions. For example, the OpenAI embedding model has 1,536 dimensions.请注意,在下图中,矢量化如何能够捕获语义表示(即,它知道谈论一只鸟猛扑到小花栗鼠身上的句子应该位于(小动物)象限中,而谈论关于昨天的暴风雨,当一棵大树倒在路上时,应该在(大,树)象限)。事实上,存在不止两个维度。例如,OpenAI 嵌入模型有 1,536 个维度。

Obtaining embeddings is quite easy from OpenAI’s embedding model. For this blog, we will use OpenAI embedding and LLM models. The OpenAI embedding model costs $0.10 /1M tokens, where each token is roughly 3/4th a word. A token is a word/subword. When text is passed through a tokenizer, it encodes the input based on a specific scheme and emits specialized vectors that can be understood by the LLM. The cost is quite minimal — roughly 10 cents per 3000 pages, but can add up as the number of documents and users scale up.从 OpenAI 的嵌入模型中获取嵌入非常容易。在本博客中,我们将使用 OpenAI 嵌入和 LLM 模型。 OpenAI 嵌入模型的成本为 0.10 美元/100 万个代币,其中每个代币大约是一个单词的 3/4。标记是一个单词/子单词。当文本通过分词器时,它会根据特定方案对输入进行编码,并发出法学硕士可以理解的专用向量。成本非常低——每 3000 页大约 10 美分,但随着文档和用户数量的增加,成本也会增加。
import openai
from getpass import getpass
api_key = getpass('Enter the OpenAI API Key in the cell ')
client = openai.OpenAI(api_key=api_key)
openai.api_key =api_key
def get_embedding(text, model="text-embedding-ada-002"):
return client.embeddings.create(input = [text], model=model).data[0].embedding
#A
e1=get_embedding('the boy went to a party')
e2=get_embedding('the boy went to a party')
e3=get_embedding("""We found evidence of bias in our models via running the SEAT (May et al, 2019) and the Winogender (Rudinger et al, 2018) benchmarks. Together, these benchmarks consist of 7 tests that measure whether models contain implicit biases when applied to gendered names, regional names, and some stereotypes.
For example, we found that our models more strongly associate (a) European American names with positive sentiment, when compared to African American names, and (b) negative stereotypes with black women.""")
#A Let's now get the embeddings of a few sample texts below.
The first two texts (corresponding to embeddings e1 and e2) are the same, so we would expect their embeddings to be the same, while the third text is completely different. To find the similarity between embedding vectors, we use cosine similarity. Cosine similarity measures the similarity between two vectors, measured by the cosine of the angle between the two vectors. Cosine similarity of 0 means that these texts are completely different, whereas cosine similarity of 1 implies identical or near identical text. We use the query below to find the cosine similarity:前两个文本(对应于嵌入 e1 和 e2)是相同的,因此我们期望它们的嵌入相同,而第三个文本则完全不同。为了找到嵌入向量之间的相似度,我们使用余弦相似度。余弦相似度衡量两个向量之间的相似度,通过两个向量之间的角度的余弦来衡量。余弦相似度为 0 意味着这些文本完全不同,而余弦相似度为 1 意味着相同或接近相同的文本。我们使用下面的查询来查找余弦相似度:
1-spatial.distance.cosine(e1,e2)
Output:
1
1-spatial.distance.cosine(e1,e3)
Output:
0.69
SAs you can see, the cosine similarity (1-the cosine distance) is 1 for theSA 如您所见,余弦相似度(1-余弦距离)为 1
Vector Embeddings For Finding Relevant Context用于查找相关上下文的向量嵌入
Let’s now see how well vector embeddings do for choosing the right context for answering a question. Let’s say we want to ask this question, corresponding to Q1 2023 for Amazon and ask the question below:现在让我们看看向量嵌入在选择正确的上下文来回答问题方面效果如何。假设我们想问这个问题,对应于亚马逊 2023 年第一季度,并提出以下问题:
prompt="""What was the sales increase for Amazon in the first quarter?"""
We can get the answer from the GPT3.5 (ChatGPT) API as below:
def get_completion(prompt, model="gpt-3.5-turbo"):
response = openai.chat.completions.create(
model="gpt-3.5-turbo",
temperature=0,
messages=[{"role": "user", "content": prompt}]
) #A
return response.choices[0].message.content
Answer:
The sales increase for Amazon in the first quarter was 9%, with net sales increasing to $127.4 billion compared to $116.4 billion in the first quarter of 2022. Excluding the impact of foreign exchange rates, the net sales increased by 11% compared to the first quarter of 2022.
#A calling OpenAI Completions endpoint
As you can see, while the above answer is not wrong, it is not the one we are looking for (we are looking for the sales increase for Q1 2023, not Q1 2022). So it is important to feed the right context to the LLM — in this case, this would be context related to sales performance in Q1 2023. Let’s say we have a choice of the three contexts below to append to the LLM:正如您所看到的,虽然上述答案没有错误,但它不是我们正在寻找的答案(我们正在寻找 2023 年第一季度的销售额增长,而不是 2022 年第一季度的销售额增长)。因此,为 LLM 提供正确的背景非常重要 – 在本例中,这将是与 2023 年第一季度销售业绩相关的背景。假设我们可以选择以下三个背景来附加到 LLM:
#A Below are three contexts, from which the relevant ones need to be chosen, related to the user inputs (sales performance in Q1 2023)
context1="""Net sales increased 9% to $127.4 billion in the first quarter, compared with $116.4 billion in first quarter 2022.
Excluding the $2.4 billion unfavorable impact from year-over-year changes in foreign exchange rates throughout the
quarter, net sales increased 11% compared with first quarter 2022.
North America segment sales increased 11% year-over-year to $76.9 billion.
International segment sales increased 1% year-over-year to $29.1 billion, or increased 9% excluding changes
in foreign exchange rates.
AWS segment sales increased 16% year-over-year to $21.4 billion."""
context2="""Operating income increased to $4.8 billion in the first quarter, compared with $3.7 billion in first quarter 2022. First
quarter 2023 operating income includes approximately $0.5 billion of charges related to estimated severance costs.
North America segment operating income was $0.9 billion, compared with operating loss of $1.6 billion in
first quarter 2022.
International segment operating loss was $1.2 billion, compared with operating loss of $1.3 billion in first
quarter 2022.
AWS segment operating income was $5.1 billion, compared with operating income of $6.5 billion in first
quarter 2022.
"""
context3="""Net income was $3.2 billion in the first quarter, or $0.31 per diluted share, compared with net loss of $3.8 billion, or
$0.38 per diluted share, in first quarter 2022. All share and per share information for comparable prior year periods
throughout this release have been retroactively adjusted to reflect the 20-for-1 stock split effected on May 27, 2022.
• First quarter 2023 net income includes a pre-tax valuation loss of $0.5 billion included in non-operating
expense from the common stock investment in Rivian Automotive, Inc., compared to a pre-tax valuation loss
of $7.6 billion from the investment in first quarter 2022."""
Measuring the cosine similarity between the query embeddings and three context embeddings, shows that the context1 has the highest cosine similarity with the query embeddings. Thus, appending this context to the user input and sending it to the LLM is more likely to give an answer relevant to the user input. We can feed this relevant context into the prompt as follows:测量查询嵌入和三个上下文嵌入之间的余弦相似度,表明上下文 1 与查询嵌入具有最高的余弦相似度。因此,将此上下文附加到用户输入并将其发送到法学硕士更有可能给出与用户输入相关的答案。我们可以将相关上下文输入到提示中,如下所示:
prompt=f”””What was the sales increase for Amazon in the first quarter based on the context below?
Context:
```
{context1}
```
"""
print(get_completion(prompt))
The answer given by the LLM is now the one we wanted as below, since it is the sales increase for Q1 2023:现在 LLM 给出的答案就是我们想要的答案,如下所示,因为它是 2023 年第一季度的销售额增长:
The sales increase for Amazon in the first quarter was 9% based on the reported net sales of $127.4 billion compared to $116.4 billion in the first quarter of the previous year.亚马逊第一季度的销售额增长了 9%,其净销售额为 1,274 亿美元,而去年第一季度的净销售额为 1,164 亿美元。
Augmented Generation 增强一代
The steps discussed above are for preparing documents for when the user interacts with the RAG application by posing a query.上面讨论的步骤是为了当用户通过提出查询与 RAG 应用程序交互时准备文档。
In this section we are going to look at how to use the chunked, embedded information as relevant context when the user queries the application. This step is to retrieve the context in real-time based on user input, and use the retrieved context to generate the LLM output. Let’s take the example that the user input is the question “What was the sales increase for Amazon in the first quarter?” based on the 10-Q Amazon document for Q1 2023. To answer this question, we have to first find the right contexts from the document chunks created above.在本节中,我们将了解当用户查询应用程序时如何使用分块的嵌入信息作为相关上下文。此步骤是根据用户输入实时检索上下文,并使用检索到的上下文生成 LLM 输出。举个例子,用户输入的问题是“亚马逊第一季度的销售额增长了多少?”基于 2023 年第一季度的 10-Q 亚马逊文档。要回答这个问题,我们必须首先从上面创建的文档块中找到正确的上下文。
Let’s define a create_context function for this. As you can see, the create_context function below requires three inputs for this — the user input query to embed, the dataframe containing the documents to find the subset of relevant context(s) to the user input, and the maximum context length, as shown the figure below.让我们为此定义一个 create_context 函数。正如您所看到的,下面的 create_context 函数为此需要三个输入 – 要嵌入的用户输入查询、包含文档的数据帧(用于查找与用户输入相关的上下文子集)以及最大上下文长度,如图所示如下图。

The logic here is to get the embeddings for the question as in the figure above, compute pairwise distances between the input query embedding, and context embeddings (step 2), and append these contexts, ranked by similarity (step 3). If the running context length is greater than the maximum context length, the context is truncated. Finally, both the user query and relevant context are sent to the LLM, for generating the output.这里的逻辑是获取问题的嵌入,如上图所示,计算输入查询嵌入和上下文嵌入之间的成对距离(步骤 2),并附加这些上下文,按相似度排名(步骤 3)。如果运行上下文长度大于最大上下文长度,则上下文将被截断。最后,用户查询和相关上下文都被发送到 LLM,用于生成输出。
def create_context(question: str, df: pd.DataFrame,max_len: int = 1800) -> str:
"""
Create a context for a question by finding the most similar context from the dataframe
"""
q_embeddings = get_embedding(question) #A
df['distances'] = df['embeddings'].apply(lambda x: spatial.distance.cosine(q_embeddings,x)) #B
returns = []
cur_len = 0
for i, row in df.sort_values('distances', ascending=True).iterrows(): #C
cur_len += row['n_tokens'] #D
if cur_len > max_len: #E
break
returns.append(row["text"]) #F
return "\n\n###\n\n".join(returns) #G
)
#A Get the embeddings for the question
#B Get the distances from the embeddings
#C Sort by distance and add the text to the context until the context is too long
#D Add the length of the text to the current length
#E If the context is too long, break
#F Else add it to the text that is being returned
#G Return the context
Here is the query and corresponding partial context created from running this line below:
create_context("What was the sales increase for Amazon in the first quarter",df)
AMAZON.COM ANNOUNCES FIRST QUARTER RESULTS\nSEATTLE — (BUSINESS WIRE) April 27, 2023 — Amazon.com, Inc. (NASDAQ: AMZN) today announced financial results \nfor its first quarter ended March 31, 2023. \n•\nNet sales increased 9% to $127.4 billion in the first quarter, compared with $116.4 billion in first quarter 2022.\nExcluding the $2.4 billion unfavorable impact from year-over-year changes in foreign exchange rates throughout the\nquarter, net sales increased 11% compared with first quarter 2022.\n•\nNorth America segment sales increased 11% year-over-year to $76.9 billion….
As you can see, the context is quite relevant. However, this is not formatted well. This is where the LLM shines as below, where the LLM can answer the questions from the created context:正如您所看到的,上下文非常相关。然而,这并没有被很好地格式化。这就是法学硕士的闪光点,如下所示,法学硕士可以从创建的背景中回答问题:
def answer_question(
df: pd.DataFrame,
question: str
):
"""
Answer a question based on the most similar context from the dataframe texts
"""
context = create_context(
question,
df
)
prompt=f"""Answer the question based on the context provided.
Question:
```{question}.```
Context:
```{context}```
"""
response = openai.chat.completions.create(
model="gpt-3.5-turbo",
temperature=0,
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
Finally, here is the corresponding answer generated from the query, and dataframe:最后,这是从查询和数据帧生成的相应答案:
answer_question(df, question=”What was the sales increase for Amazon in the first quarter”)
The sales increase for Amazon in the first quarter was 9%, reaching $127.4 billion compared to $116.4 billion in the first quarter of 2022.亚马逊第一季度销售额增长 9%,达到 1274 亿美元,而 2022 年第一季度销售额为 1164 亿美元。
Congratulations, you have now built your first RAG app. While this works well for questions where the answer is explicit within the text context, the answer is not always accurate when retrieved from tables. Let’s ask the question “What was the Comprehensive income (loss) for Amazon for the Three Months Ended March 31, 2022?” — where the answer is present in a table as $ 4,833 million as shown in the figure below:恭喜,您现在已经构建了第一个 RAG 应用程序。虽然这对于文本上下文中答案明确的问题很有效,但从表格中检索答案并不总是准确的。让我们问一个问题“截至 2022 年 3 月 31 日的三个月,亚马逊的综合收入(亏损)是多少?” — 答案在表格中为 48.33 亿美元,如下图所示:

The answer from the application is:应用程序的答案是:
The Comprehensive income (loss) for Amazon for the Three Months Ended March 31, 2022 was a net loss of $3.8 billion.截至 2022 年 3 月 31 日的三个月,亚马逊的综合收入(亏损)为净亏损 38 亿美元。
As you can see, it gave the net income (loss), instead of the comprehensive income (loss). This illustrates the limitations of the basic RAG architecture we built.正如您所看到的,它给出的是净利润(损失),而不是综合收益(损失)。这说明了我们构建的基本 RAG 架构的局限性。
In the next blog, we will learn about advanced document extraction, chunking, and retrieval mechanisms that build on the concepts learnt here. We will learn about evaluating the quality of responses from our RAG application using various metrics. We will learn how to use different techniques, guided by evaluation results, and make iterative improvements to performance.在下一篇博客中,我们将了解基于此处学到的概念的高级文档提取、分块和检索机制。我们将了解如何使用各种指标评估 RAG 应用程序的响应质量。我们将学习如何在评估结果的指导下使用不同的技术,并对性能进行迭代改进。
You can find the code to this here:您可以在这里找到相关代码:
RAG-From-Scratch/Ch2/Ch02_walkthrough.ipynb at main · skandavivek/RAG-From-ScratchRAG-From-Scratch/Ch2/Ch02_walkthrough.ipynb 位于 main · skandavivek/RAG-From-Scratch
RAG is becoming the standard to customize the output of LLMs for domain specific applications with data. Learn how to…RAG 正在成为使用数据为特定领域应用程序定制 LLM 输出的标准。了解如何…
github.com github.com
If you like this post, follow EMAlpha — where we dive into the intersections of AI, finance, and data.如果您喜欢这篇文章,请关注 EMAlpha——我们将深入探讨人工智能、金融和数据的交叉点。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...







