
原文链接:https://mixshare.zhubai.love/posts/2249818679560949760
众所周知,ChatGPT是目前非常火爆的对话聊天机器人,但它的本质是个大语言模型。在本文中,我将简要介绍一下语言模型的基本概念,并结合最近在笔记本电脑上成功运行的distilbert-base-uncased为实例,探讨人人都可以拥有一个属于自己的语言模型的时代如何到来。
科普:什么是语言模型LLM?
简单来说,语言模型LLM(Large Language Model)是一种基于概率的算法,用于计算一段文本的可能性。其核心思想是预测给定单词序列中的下一个单词。语言模型通过学习大量文本数据,掌握语言的语法、语义和常见用法等知识,从而为自然语言处理(NLP)任务提供基础支持。常见的应用场景包括机器翻译、语音识别、文本摘要等。
图片加载中
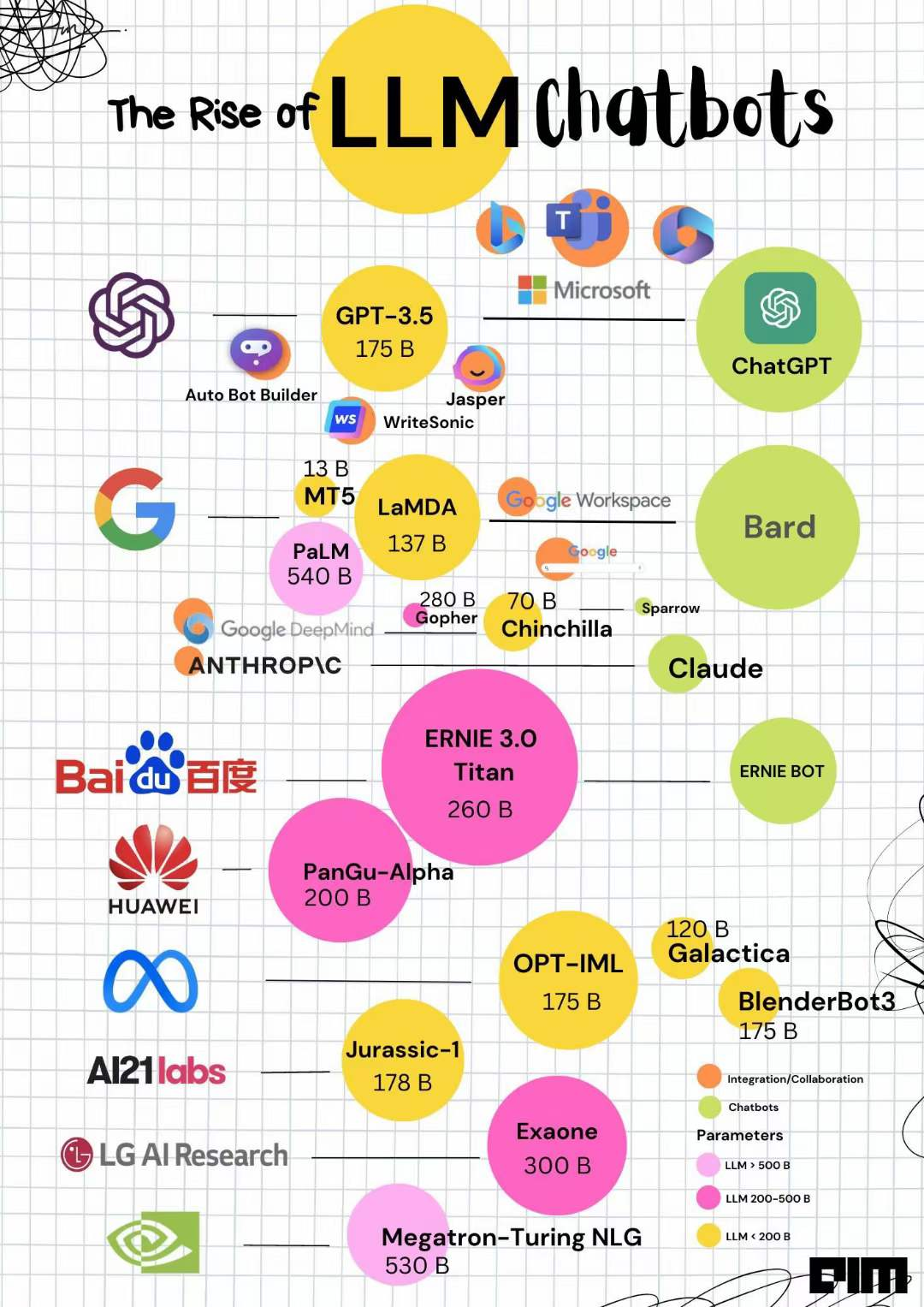
AGI | 通用人工智能大语言模型及聊天机器人🤖们的崛起与关系 | 觅学札记
近年来,随着深度学习技术的发展,语言模型发生了翻天覆地的变化。尤其是基于Transformer架构的大型预训练模型,如BERT、GPT等,它们通过对海量文本数据进行预训练,获得了丰富的语言知识和表达能力。这些模型可以通过简单的微调,应用于各种NLP任务,并取得了极高的性能。正是这样的模型,为聊天机器人Chatbots提供了强大的驱动力。
举例:个人用户如何跑语言模型?
而现在,有了开源框架和大量预训练模型的支持,使得我们不再需要昂贵的计算资源和深厚的专业知识,就可以在自己的电脑上运行语言模型。
例如,刚刚我就在笔记本电脑上成功运行的distilbert-base-uncased-finetuned-sst-2-english,这是一个基于DistilBERT模型的情感分析模型,具有较小的模型体积和较高的运行效率。
不懂的地方询问ChatGPT,它会不厌其烦事无巨细地告诉你详细步骤⤵️
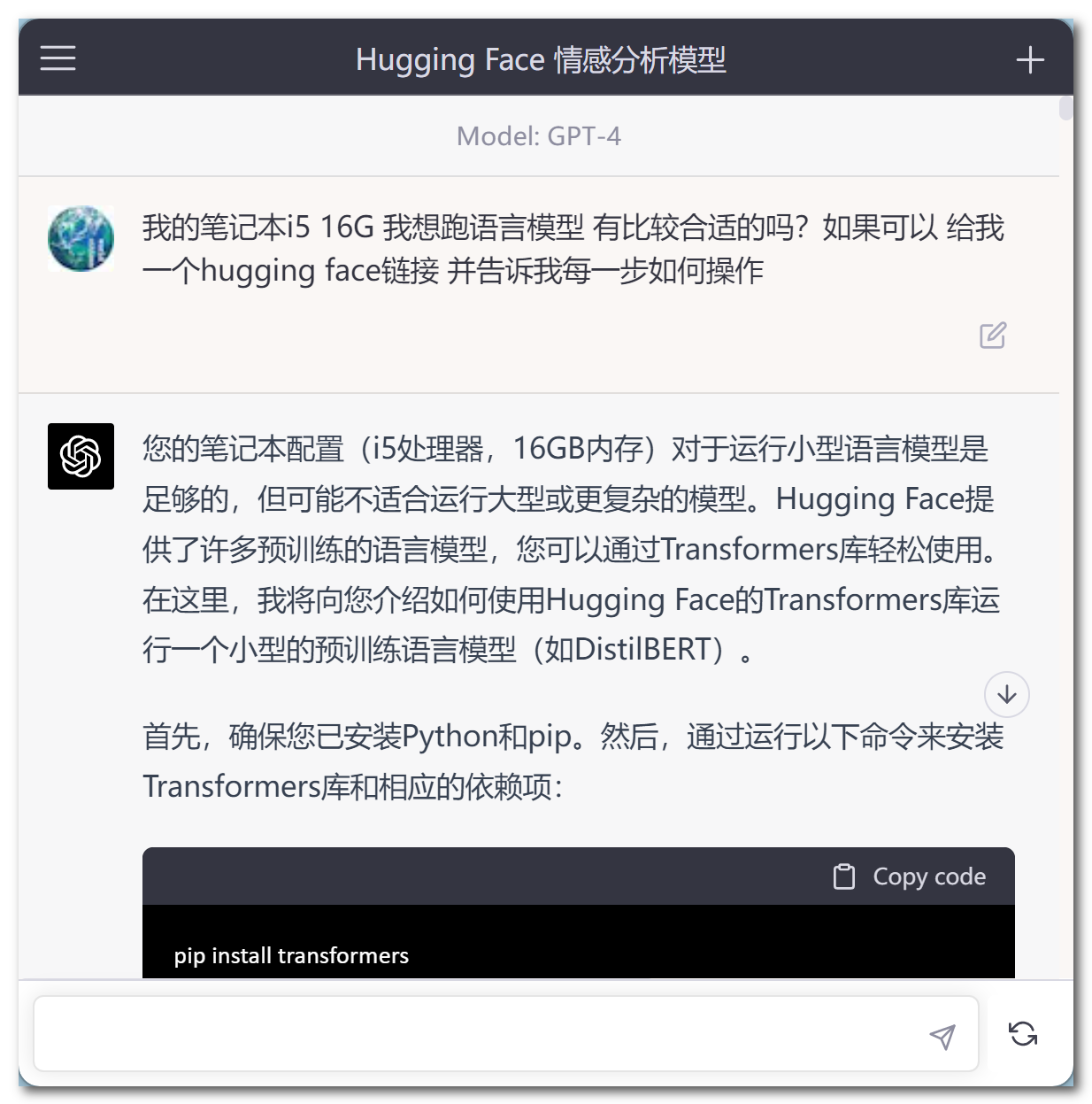
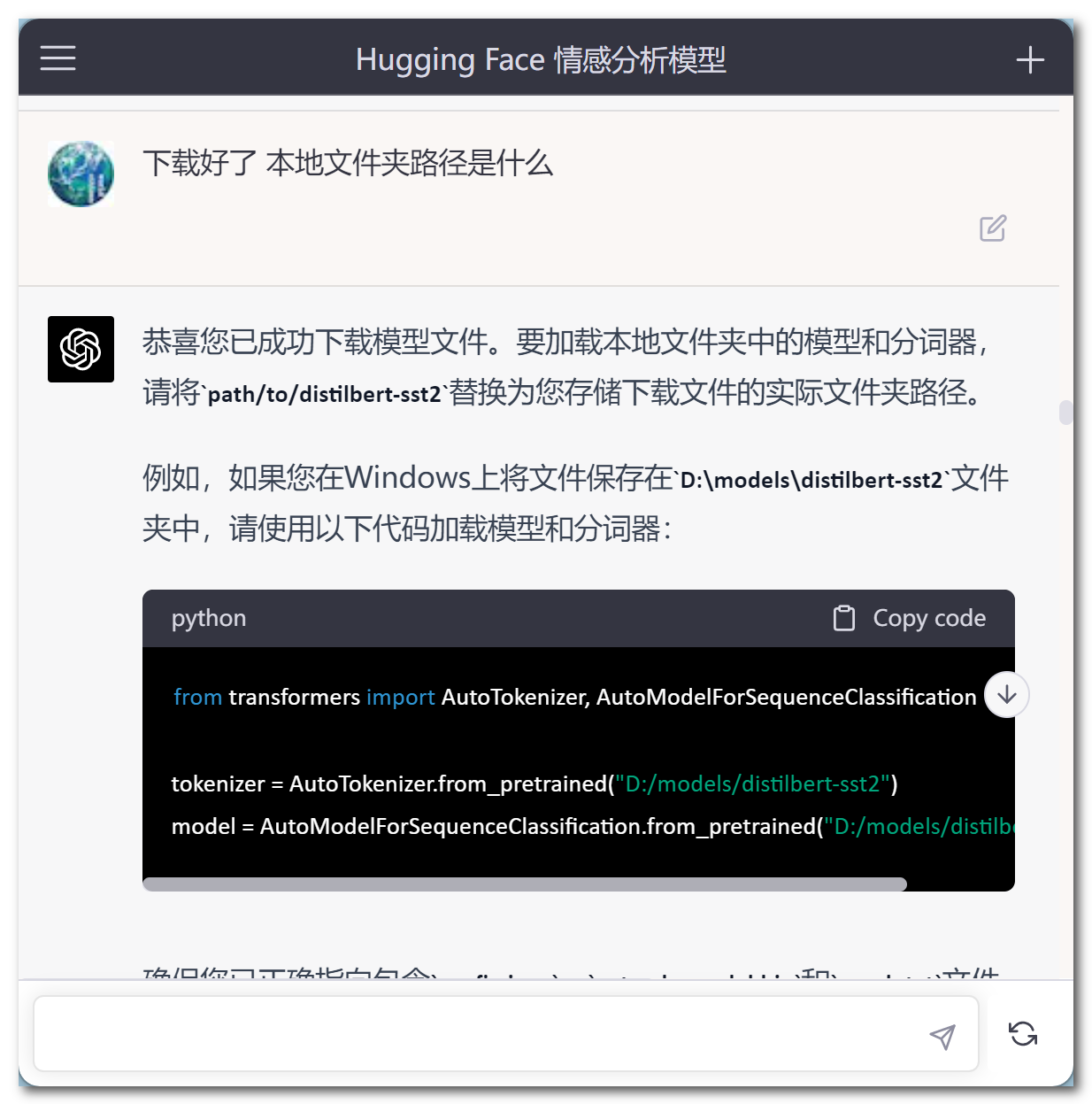
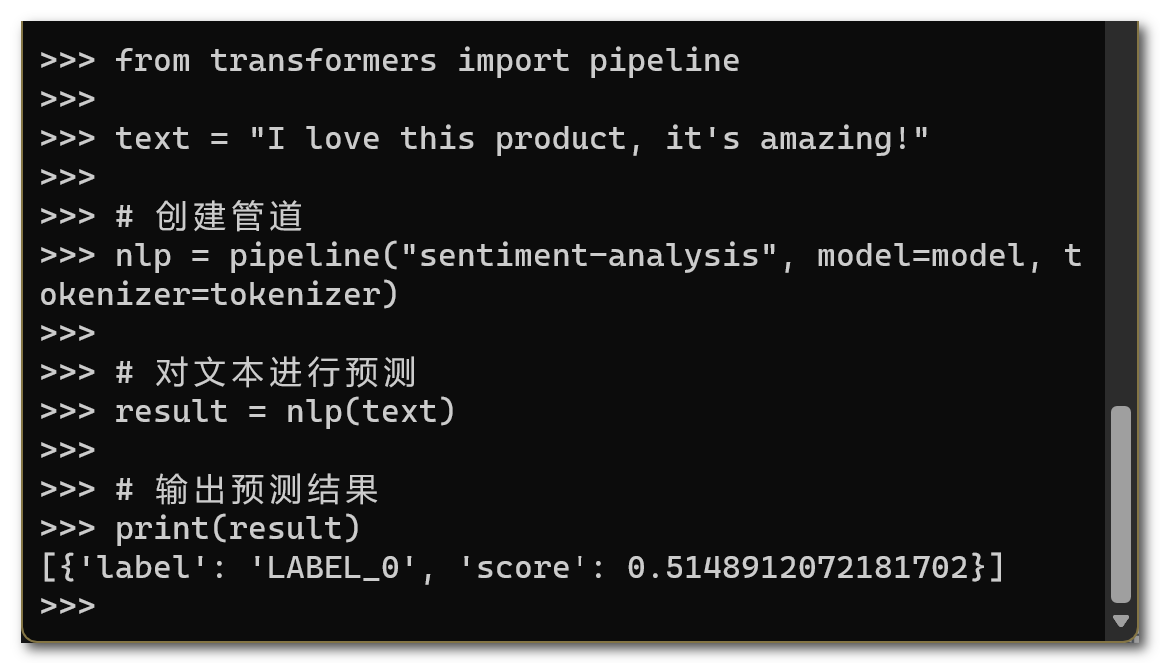
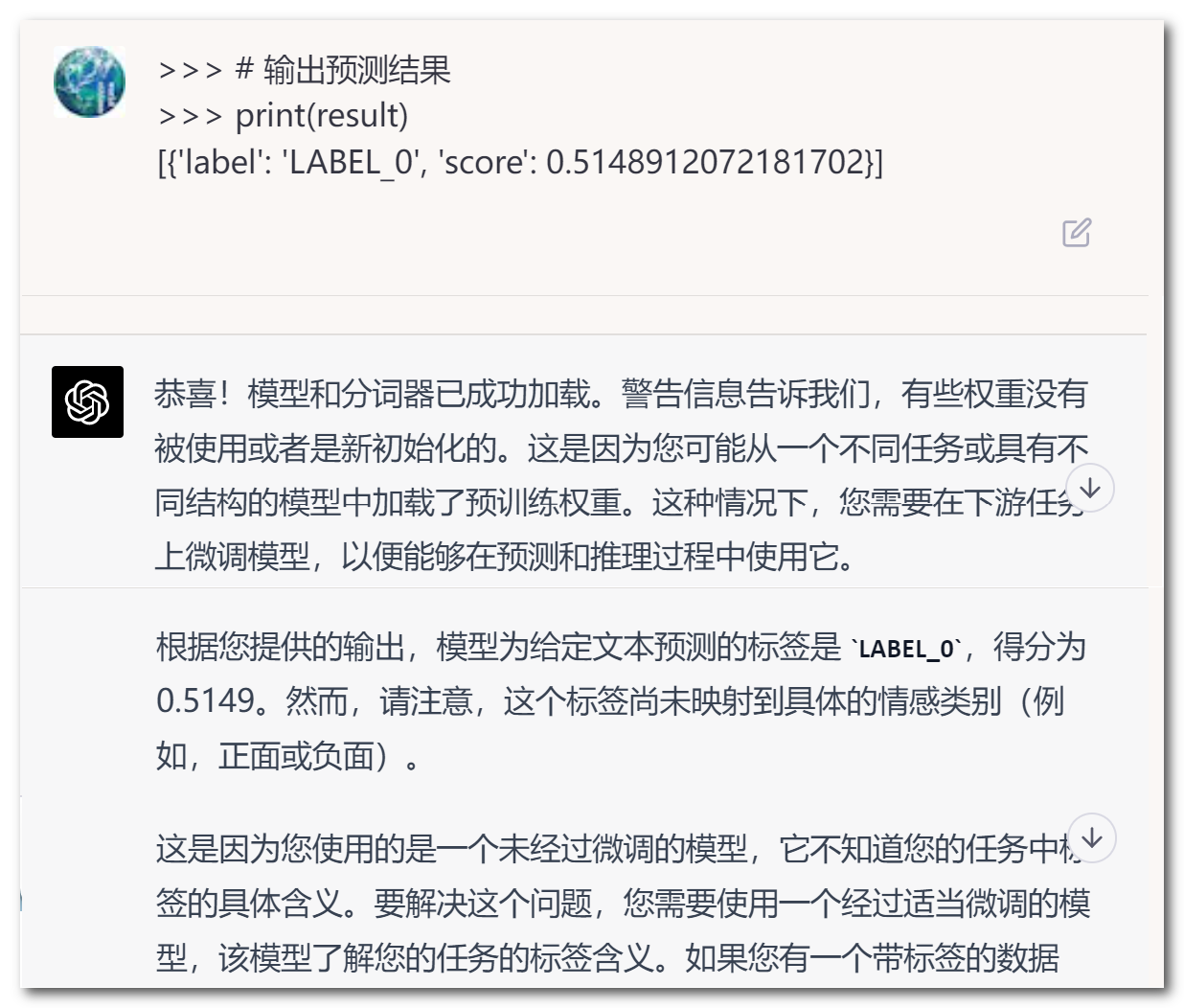
通过动手实践操作,让我对大语言模型LLMs 的训练有了更直观的了解✅,我相信这也是一个探索更多精彩的开始。
未来:人人都可以有属于自己的语言模型吗?
通过上面的例子,你应该也看到了,即使在性能一般的设备上,我们也可以运行这样的语言模型,并且随着语言模型将不断升级,性能将更加优越,模型体积也会变得更小,这将使得更多的设备能够轻松地运行这些模型。
同时,开发者们可以通过不断优化算法和提高模型效率,让普通用户在日常生活和工作中更加便捷地使用人工智能技术。
另外,随着个性化需求的增长,定制化的语言模型也将逐渐成为一种趋势。我们可以期待,未来将出现更多面向特定任务或领域的语言模型,它们可以为用户提供更加精准、高效的服务。

by Midjourney | Prompt:Each person has their own customized large language model:: anime::1 cartoon::1 concert lighting::1 fluorescent::1 diego rivera::1 henri matisse::1 paul klee::1 paper::1 --v 4
总结:语言模型普及的未来可期 但挑战与风险并存
综上所述,人人都可以在自己的电脑上跑语言模型的时代已经到来,这将极大地拓宽普通用户在人工智能领域的发挥空间,推动各行各业的变革和发展。

当然,我们也要意识到,普及语言模型的同时,可能会带来一些伦理和安全方面的挑战。例如,如何防止语言模型用于制造虚假信息、散播仇恨言论等。因此,研究者和工程师需要在技术创新的同时,关注潜在的风险,并采取相应的措施确保人工智能技术的健康、可持续发展。
在这个过程中,我们既要享受技术带来的便利,也要积极应对挑战,共同构建一个更智能、更美好的未来。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...







